XPath (XML Path Language) is a query language for selecting nodes from an XML document. It’s widely used in web scraping (e.g., Selenium, Scrapy) to locate elements in HTML.
视频解说点这里
XPath Syntax Cheat Sheet Component Expression Example Description Node Selection //html/body/divSelects from the root node. ////divSelects nodes in the document from the current node that match the selection no matter where they are. ../divSelects the current node. ..../divSelects the parent of the current node. Attributes @//@hrefSelects attributes. Predicates []//div[@class='main']Filter expressions. Wildcards *//*Matches any element node.
Common Examples Selecting Elements //div: Select all div elements.//div/p: Select all p elements that are children of div.//div//p: Select all p elements that are descendants of div.Using Attributes //div[@id='content']: Select div with id="content".//a[@href='google.com']: Select link pointing to google.//input[@type='text']: Select text input fields.Functions contains(): //div[contains(@class, 'nav')] (Matches class="main-nav")starts-with(): //div[starts-with(@id, 'auth-')]text(): //button[text()='Submit'] (Exact match)last(): //ul/li[last()] (Select the last item)position(): //ul/li[position() < 3] (Select first two items)Axes //h1/following-sibling::p: Select p elements after h1.//p/parent::div: Select the div parent of p.Chrome DevTools : Cmd+F in Elements tab supports XPath.XPath Helper : Chrome extension for testing XPath.
| 操作符 | and, or, >=, <= … |如何使用 XPath Chrome Elements
Chrome Console
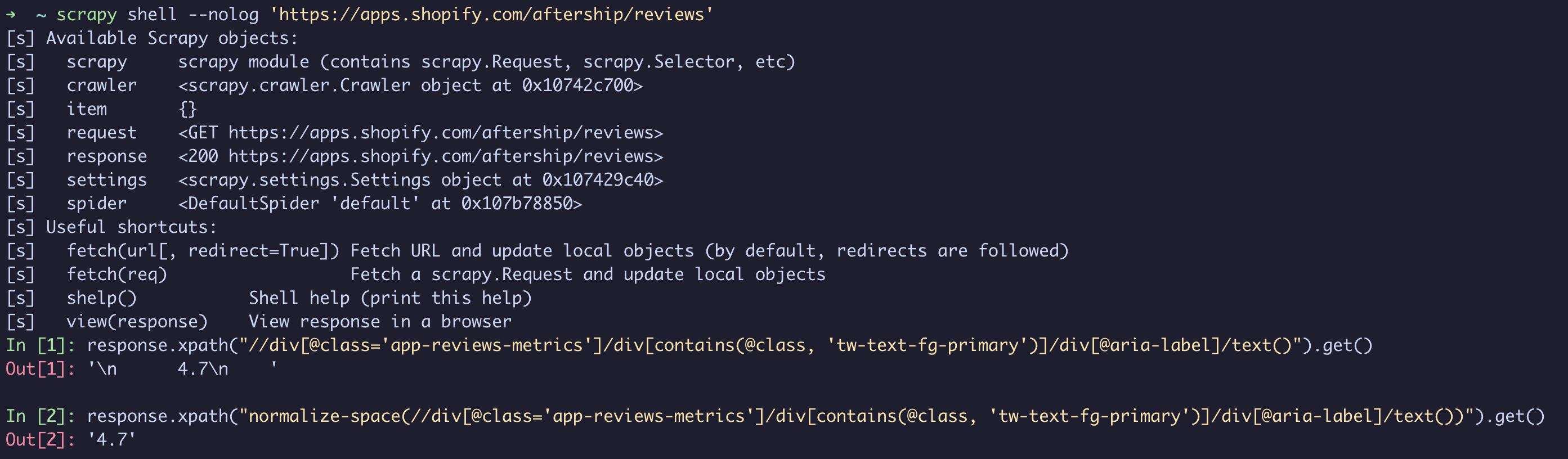
Scrapy shell
XPath 案例 XPath Comment //ul/li/a 纯节点 //button/text()[.=‘Submit’] 限定符 //a[@id=“abc”][@for=“xyz”] 多限定符 //a[@name or @href] 操作符 //a[starts-with(@href, “/”)] 函数 //ul[count(li) > 2 and li[ends-with(@class, “active”)]] 复合条件 //ul/li[last()] 位置 //h1/following-sibling::ul 轴 //div[count(./div)=2] | //tr[count(./td)=2] 合集
XPath 要注意的 11 个点 返回的是节点集合。 text() 也是节点,可以限定。 [] 可联结(Chainable: [][]), 可嵌套(Nestable: [[]])。 路径表达式可以通过 “|” 获取合集。 source code 里 tbody 标签可能不存在。 善用函数 substring-before(XPath, "split_str"), concat(XPath, XPath)。 注意函数的作用域,往往只作用于节点集的第一个节点。 当前节点它是一个引用,依然可以搜索整棵树。 可结合 re 的功能。 强烈推荐 Python package parsel,它还支持 JMESPath。 如果是 XML 类型,需要声明 namespace 及替换没有 namespace 的 soap。 参考